
At SimpleRisk, we offer a feature that allows you to map your policies, guidelines, standards, and procedures to governance frameworks and controls. The intent is straightforward: to ensure that what your documentation says you do is backed up by controls that prove you're actually doing it. But when you're working with a framework like the NIST Cybersecurity Framework (CSF), which has hundreds of controls — or worse, the Secure Controls Framework (SCF), with over 1,200 — finding the right controls to support your documentation quickly becomes a monumental challenge.
With the rise of Artificial Intelligence, you might think, “Problem solved!” Just feed everything into an AI model, ask it to match the documents to the relevant controls, and let it do the heavy lifting. I thought the same — but as it turns out, it’s not quite that simple.
The Token Trap
To understand why, we need to talk about tokens. In the world of AI, tokens are a measure of how much information a model can process at one time. Different AI models — GPT-4, Claude, Gemini, LLaMA, and others — all have token limits, which cap how much data you can send in a single request. These tokens aren't just technical limits; they're also how most AI services determine pricing.
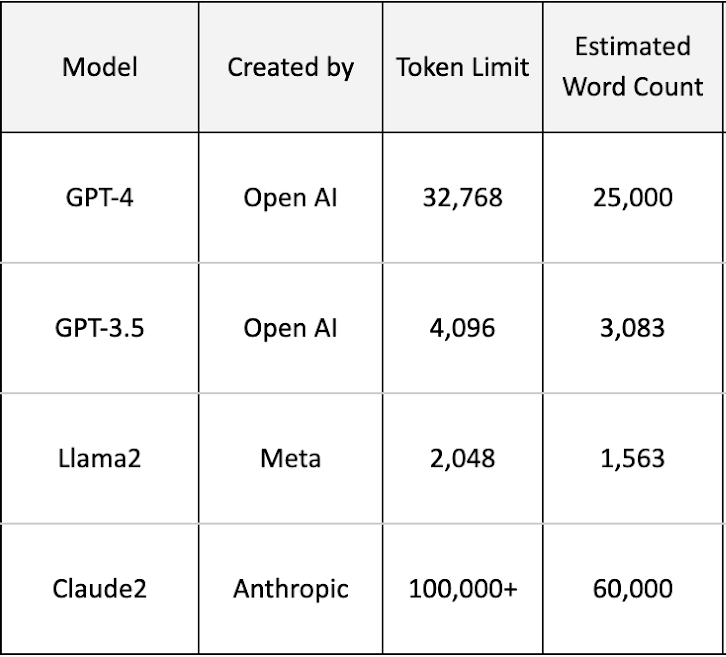
When I first began this journey, tokens became my nemesis. To compare a policy to a control properly, I needed at least the full policy text and the control description. This was fine for one-to-one matching, but things quickly spiraled out of control when I tried to scale up. Before long, I was hitting the dreaded “maximum token limit exceeded” errors.
Chunking Doesn't Scale
Research led me to the idea of batching or chunking the controls into smaller sets. Instead of sending one document against 1,200 controls at once, I’d break the controls into chunks. I started with chunks of 500 — still too big. Then 100 — still failing. Even at 50, results were inconsistent. Eventually, I got it working at around 20 controls per chunk. But just when I thought I’d won, a new problem appeared: rate limiting.
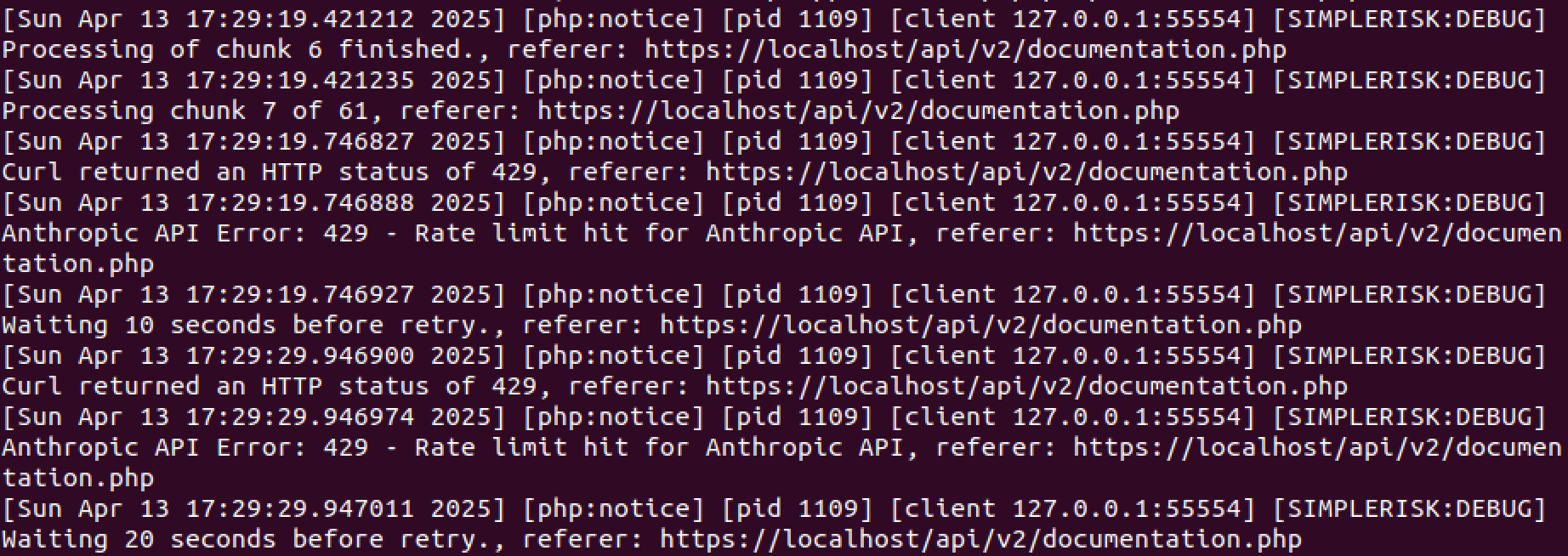
AI providers don't just limit individual requests; they also limit how many tokens you can process over time. So while I could now get through a single chunk, processing all 1,200 SCF controls meant sending 60+ requests. With rate limits in play, that either broke the process or stretched it out into hours. I could add backoff delays to avoid errors, but that made things unbearably slow. I needed a better solution.
Enter: Old-School NLP
Ironically, I turned to AI itself to help me solve the problem — and it reminded me that we’ve been doing document similarity analysis long before LLMs existed. One of the most effective traditional techniques is called TF-IDF (Term Frequency–Inverse Document Frequency).
Here's the gist:
- We start by converting each document and control into a list of terms, filtering out common stop words like “and,” “or,” and “the.”

- We then count how frequently each term appears — that’s the term frequency (TF).

- Next, we calculate how unique a term is across all documents — that’s the inverse document frequency (IDF).

- Multiply TF and IDF, and you get a TF-IDF score — a weighted value representing how important each term is in that context.
The beauty of this is that each document and control can be represented as a vector, which we can compare using cosine similarity to find related content.
If that last paragraph lost you, don’t worry — the big takeaway is this: before even involving AI, we can use keyword overlap to quickly narrow down which controls are most likely to be relevant to a given document.
From 1,200 to a Manageable Few
In my testing, TF-IDF allowed me to eliminate about 95% of irrelevant controls for any given document. That meant I could limit my AI processing to the top 5% — a much more manageable number for batching and cost purposes.
But there was still room for optimization.
Optimization #1: Preprocessing TF-IDF
Initially, I was performing TF-IDF calculations during the matching process, which introduced serious delays. But since document and control content doesn't change frequently, I decided to pre-process this data when content is added or updated and store the results in a database. Now, matching can reference this stored data instantly.
Optimization #2: Smarter AI Prompts
What most people don’t realize is that an AI request typically has two parts:
- A system prompt — which tells the model how to behave
- A message — which contains the actual data to analyze
The trick? The system prompt is often cached and doesn’t count against token limits. So I moved all the behavioral instructions — matching logic, formatting requirements, evaluation criteria — into the system prompt. That left only the unique document and control data in the message, drastically reducing token usage and cost.
Optimization #3: Scheduled Matching Jobs
Even with these improvements, AI processing across thousands of controls can take minutes — too long for users to wait in real time. So I offloaded the entire matching process to a background job. A scheduled task checks for documents that haven’t been analyzed, runs the comparisons, and stores the results for users to view later.
The End Result
All of this work culminated in a powerful new report inside SimpleRisk: Documents to Controls. It’s a filterable, sortable table that shows:
- Whether existing control-document relationships make sense
- Suggested new control mappings
- Underlying metrics like term frequency, TF-IDF scores, and AI reasoning
What used to take weeks or months to complete manually can now be accomplished in minutes — with greater consistency, accuracy, and transparency.



